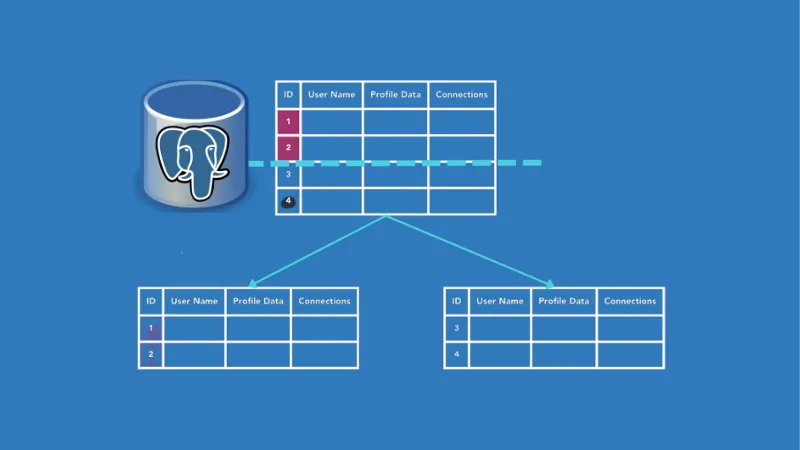
Hoje com o constante crescimento nos dados é frequente termos tabelas com milhares de registro no qual aumenta seu tamanho e assim dificultando a manutenção e manipulação desses dados. Imagine uma base de dados de um cliente de comercio no qual a tabela de vendas contem os dados de 10 anos, muitas das vezes os dados de histórico são poucos sendo que na maioria das consultas geradas serão de dados dos últimos 12 meses. Para isso contamos podemos contar com o particionamento de tabela.
O particionamento de tabela é útil a fim de dividimos uma grande tabela em partições menores dessa forma torna as consultas de geração de relatório e estatísticas menos onerosas para o banco de dados. Imagine pegarmos uma base de dados com 10 anos de informação e pegamos a tabela de vendas e segmentarmos em 3 partições no qual na última partição seria guardado dados do ano corrente? Ainda podemos unir força com o recurso de Tablespaces, no qual poderíamos criar uma tablespace em uma unidade de disco mais rápida para guardar dados do ano corrente. Dessa forma com uma boa estratégia de particionamento dos dados ao invés de acessar um tabelão com milhões de registros podemos acessar uma partição com uma poção de dados bem menor e assim exigir menos do banco de dados. Então vamos começar a configuração.
“Para entender a fundo o processo e as técnicas de particionamento de tabelas no PostgreSQL, consulte a documentação oficial.
Conteúdo
Particionamento de Tabela: Passo a passo
Criando a tabela de vendas
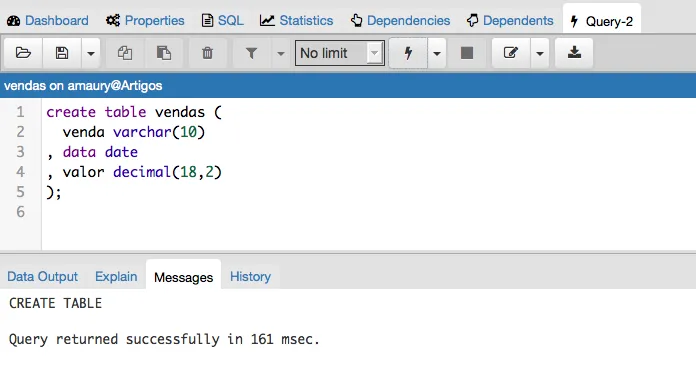
Para iniciarmos nosso exemplo vamos criar uma tabela chamada vendas.
Importação de vendas
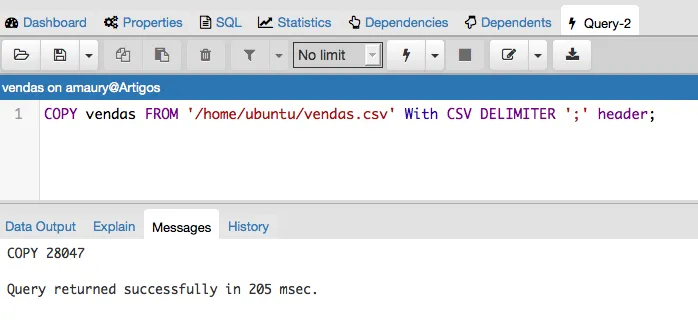
Para darmos continuidade vou importar um arquivo CSV e usar comando copy passando como parâmetro a tabela vendas e o local do arquivo CSV baixado.
Deletando as vendas
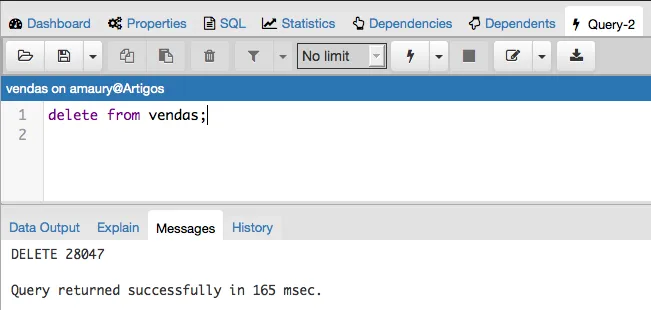
Perceba que foram importados 28.047 vendas. Os dados importados possuem vendas dos anos de 2016, 2017 e 2018, podem ficar a vontade para realizar consultas na tabela importada. Agora podemos deletar esses dados importados.
Criando tabelas particionadas
A minha ideia é particionar essa tabela vendas em 3 partições, a primeira com os dados de 2016, a segunda com os dados de 2017 e a última com os dados de 2018 e anos posteriores. Essas partições poderiam ser armazenadas em tablespaces diferentes. Para realizar a configuração precisaremos criar uma tabela para cada partição e para isso vamos usar o recurso de herança de tabela do PostgreSQL. Também precisamos definir uma chave que irá controlar o intervalo da partição nesse caso foi escolhido o campo “data” com o uso da função “extract” do PostgreSQL para conseguirmos extrair o ano da data.
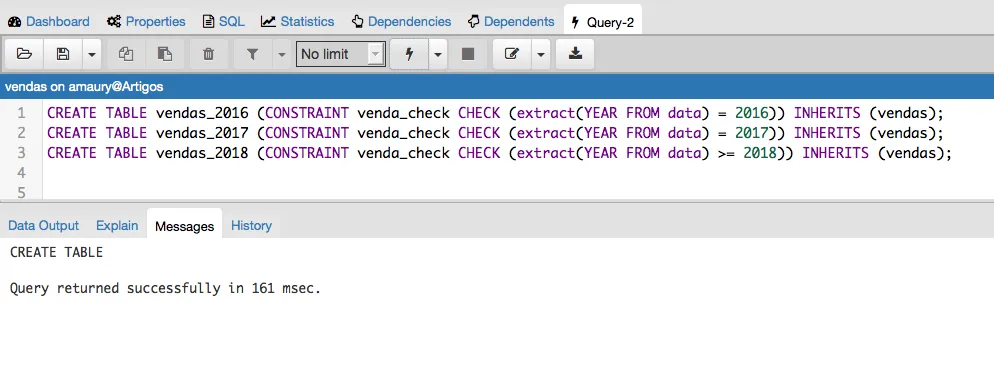
Após a criação das tabelas podemos ver que agora temos 4 tabelas.
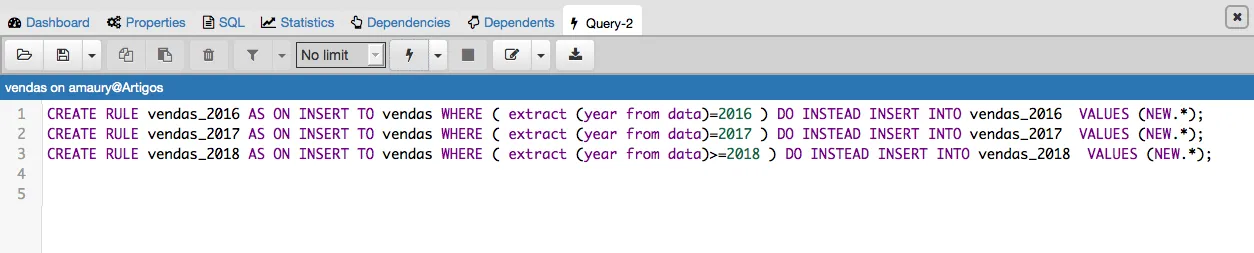
Criando as rules
Por último vamos criar 3 rules na tabela principal “Vendas” para que na inserção de novos dados os mesmos sejam realocados para suas partições respeitando a chave que controla o intervalo de partição.
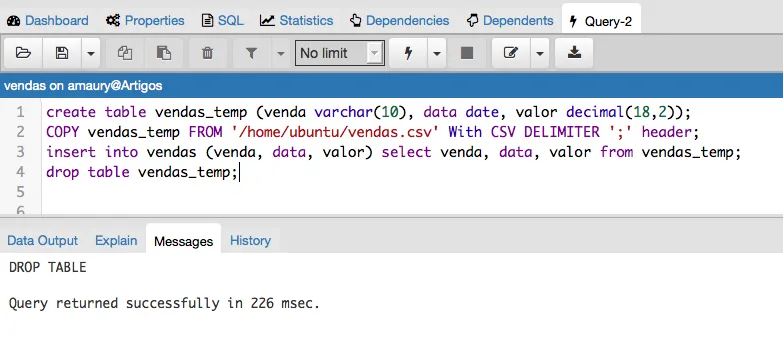
Testando particionamento de tabela
Agora vamos realizar o teste do particionamento, a rule do particionamento foi definido no comando INSERT por isso ao importarmos os dados do CSV com o comando COPY os mesmos não serão realocados dessa forma para realizarmos nosso teste vamos executar os seguintes passos: Cria uma tabela com mesma estrutura, importar os dados para essa nova tabela, inserir os dados importados da tabela temporária para a tabela vendas e por último excluir a tabela temporária criada.
Agora podemos ver o resultado final do teste com o seguinte comando.
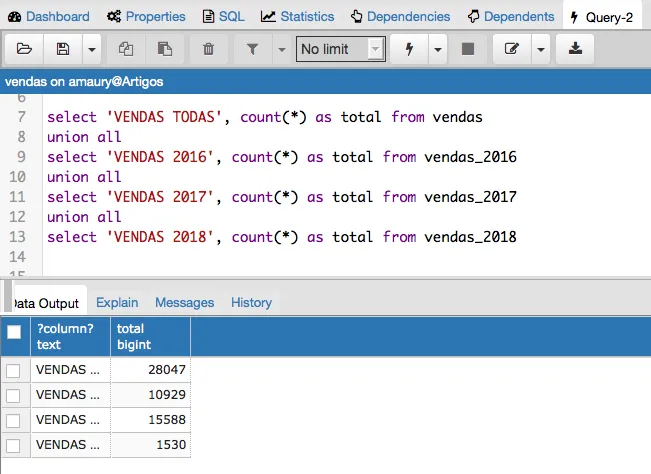
O que podemos ver é que esse recurso é transparente para para as aplicações pois as mesmas consultarão sempre a tabela principal “VENDAS” mais os dados fisicamente estarão armazenadas nas tabelas filhas, dessa forma para podermos usar o particiomaneto com eficiência, nas consultas na cláusula WHERE usar sempre a chave “data” pois se não para mostrar os dados da tabela vendas completa é preciso fazer a união das 3 tabelas filhas e ao invés de ganharmos performance estaremos perdendo. E uma outra observação é que os índices devem ser criados na tabela principal e nas tabelas filhas pois os mesmos também serão particionados e armazenados na partição junto com seus dados.
Para otimizar ainda mais suas consultas e aproveitar ao máximo a estrutura particionada, é essencial ter um bom entendimento de SQL. Convido você a aprofundar seus conhecimentos com meu artigo sobre os fundamentos de SQL para análise de dados, que fornece uma base sólida para qualquer profissional que trabalha com grandes conjuntos de dados.


